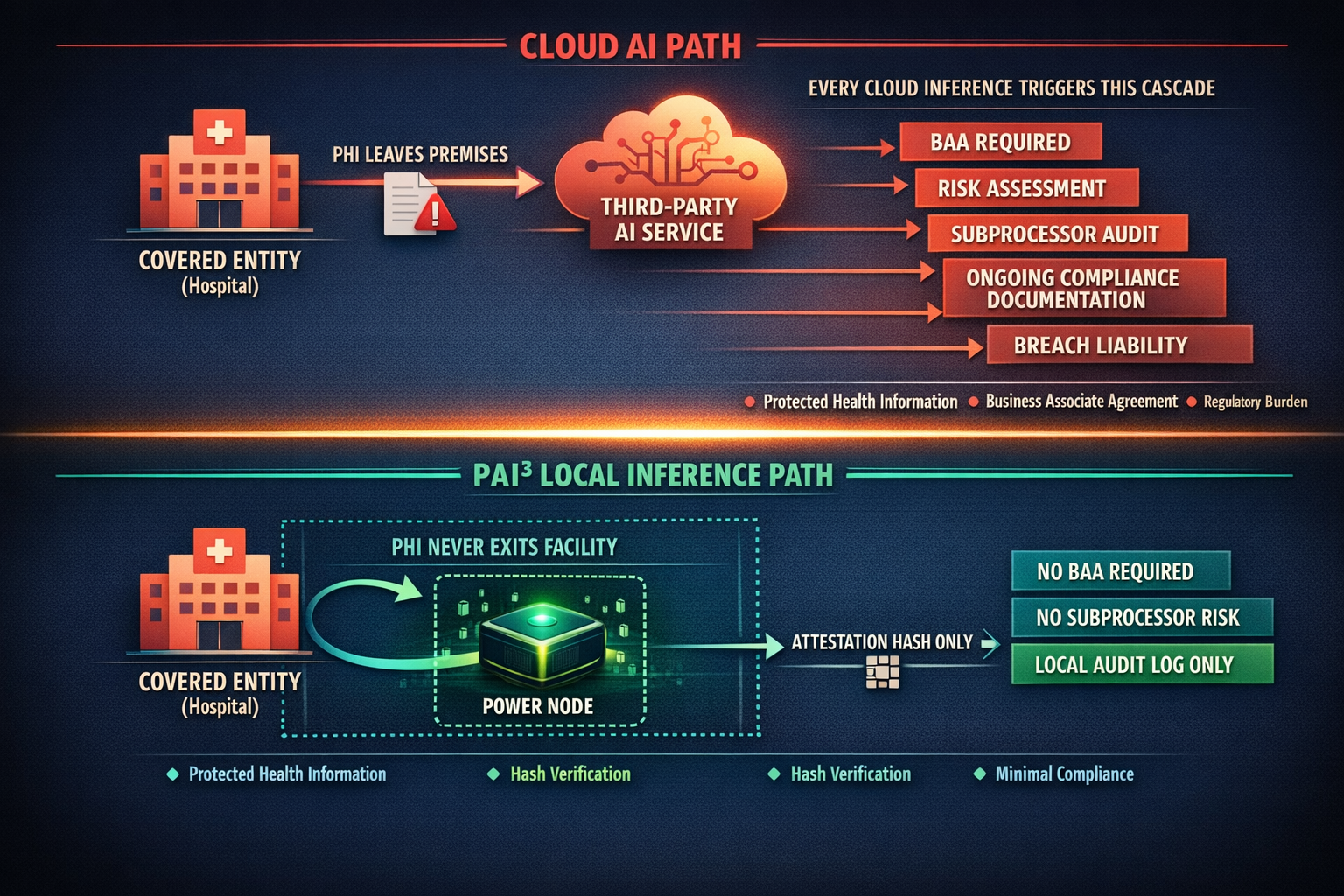
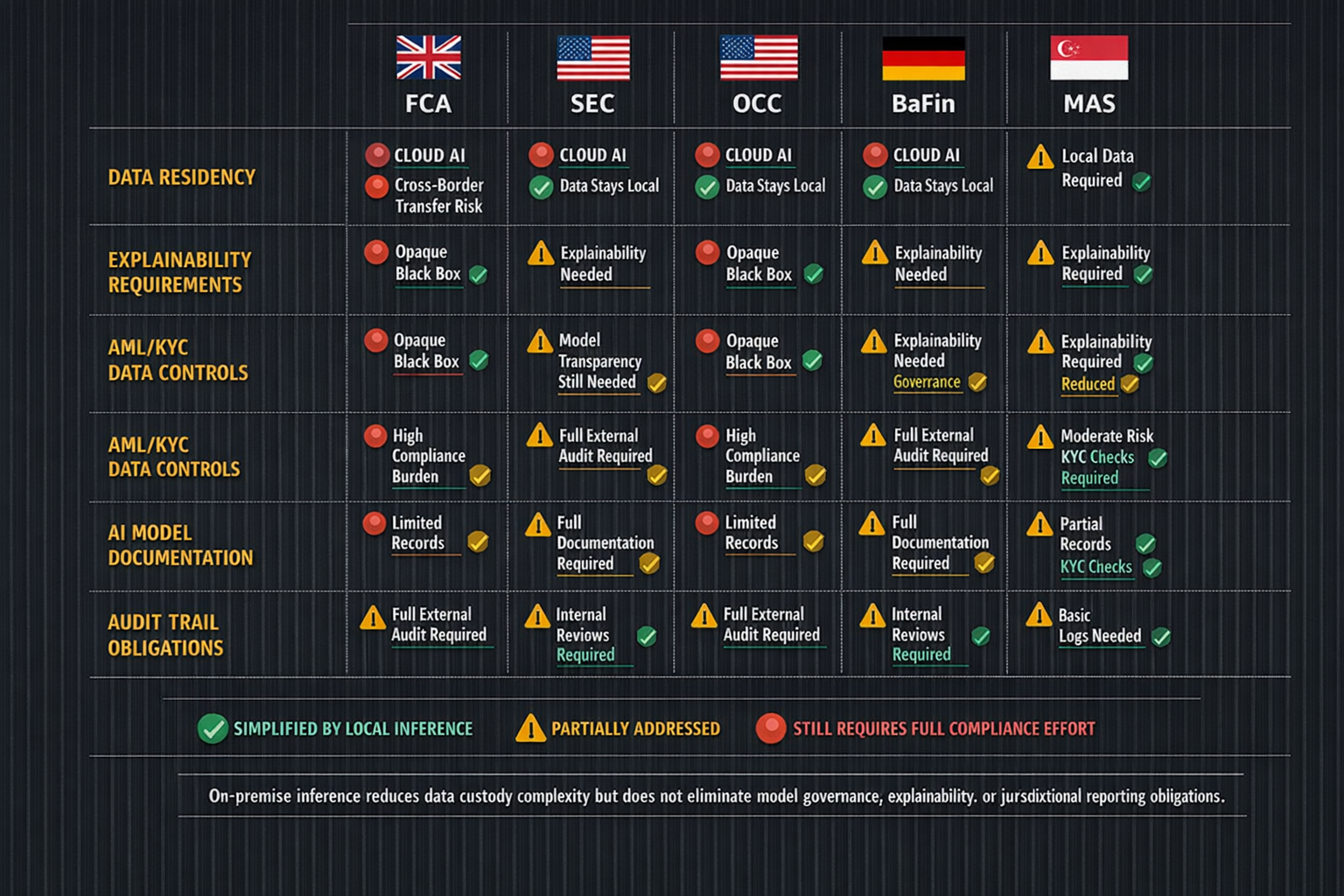
Regulated industries — healthcare providers, government agencies and financial institutions — face growing pressure to deploy AI capabilities while meeting strict data custody requirements. Most of them cannot use current offerings. Not because the models are not good enough — GPT-4, Claude, Gemini are more than capable of reading radiology scans, flagging suspicious transactions and summarising briefings. The problem is data custody. The moment a hospital sends a patient's MRI to an API endpoint operated by OpenAI, that data has left the premises. Under HIPAA, that creates a custody chain involving a third-party processor, triggering Business Associate Agreement requirements, audit obligations and liability exposure. Under the EU AI Act — which entered into force on 1 August 2024, with provisions phasing in over a multi-year timeline — high-risk AI systems processing health data face additional transparency and documentation mandates. Prohibited AI practices have been enforceable since February 2025, and general-purpose AI (GPAI) rules apply from August 2025. The most significant high-risk AI system obligations under Annex III take effect on 2 August 2026, meaning enterprises deploying AI in healthcare, finance and government should be preparing now for obligations that are weeks away from becoming enforceable. For classified government workloads, the question is even simpler: the data cannot leave the building. Period.
This is not a feature gap that can be patched with better encryption or a contractual addendum. Encrypting data in transit does not change the fact that a third party decrypts and processes it on their hardware. Data anonymisation before sending to a cloud API introduces re-identification risk — landmark studies by Sweeney (2000) and Narayanan & Shmatikov (2008) demonstrated that supposedly anonymised health and financial datasets can be reverse-engineered with auxiliary data, a finding that has been well-documented across the data privacy literature in the decades since. The compliance problem is structural: centralised AI architectures require data to move to compute. Regulated industries need compute to move to data.
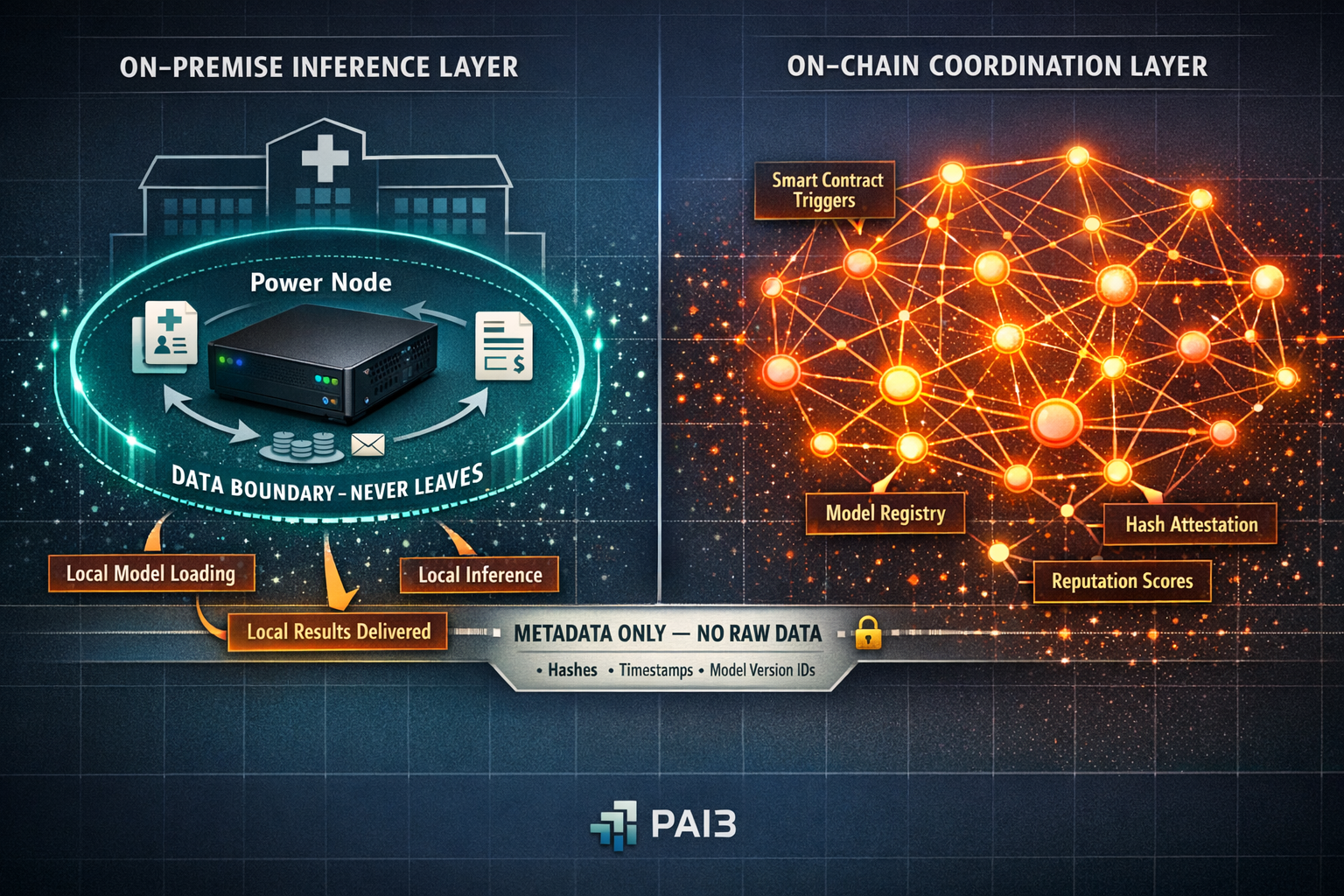
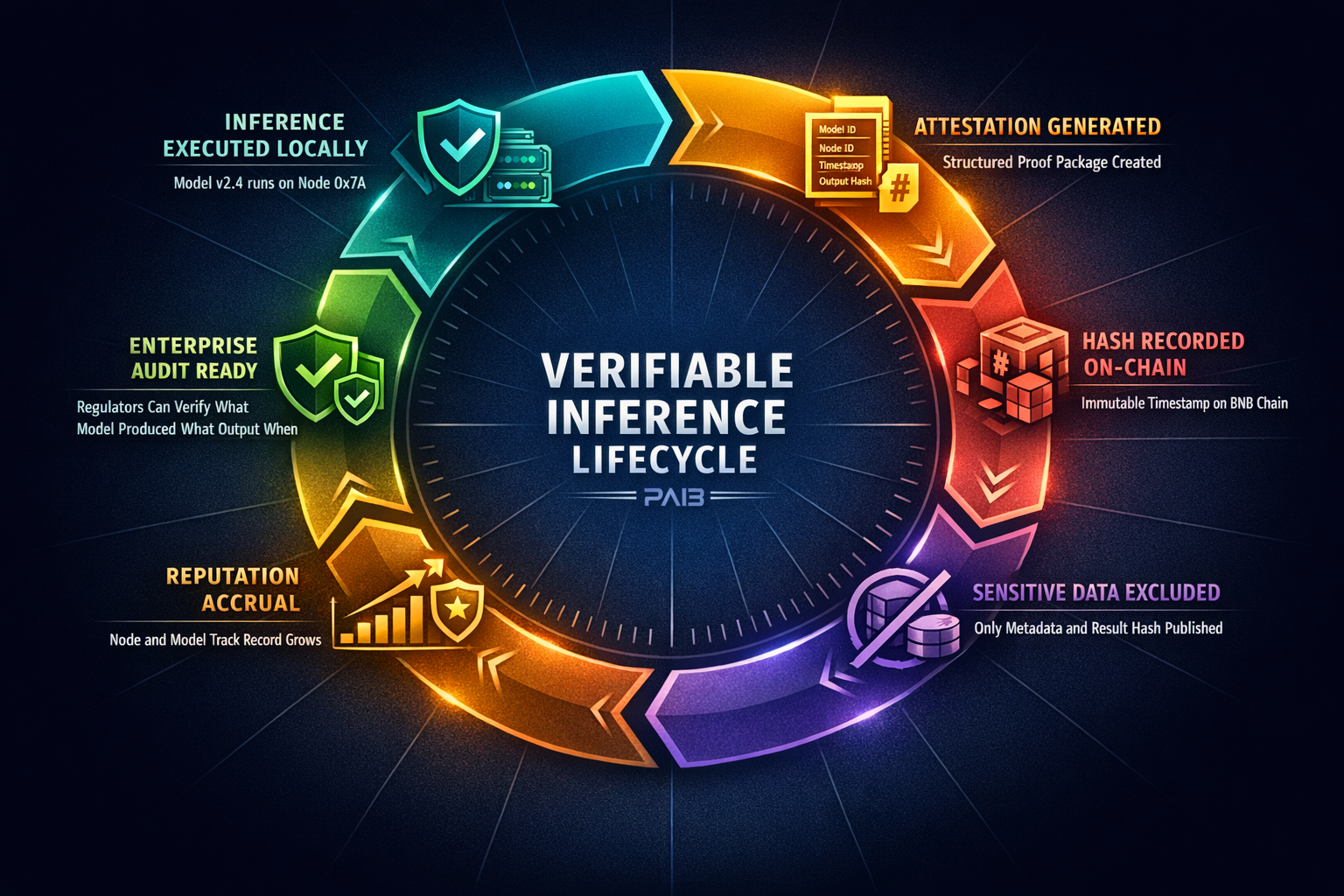
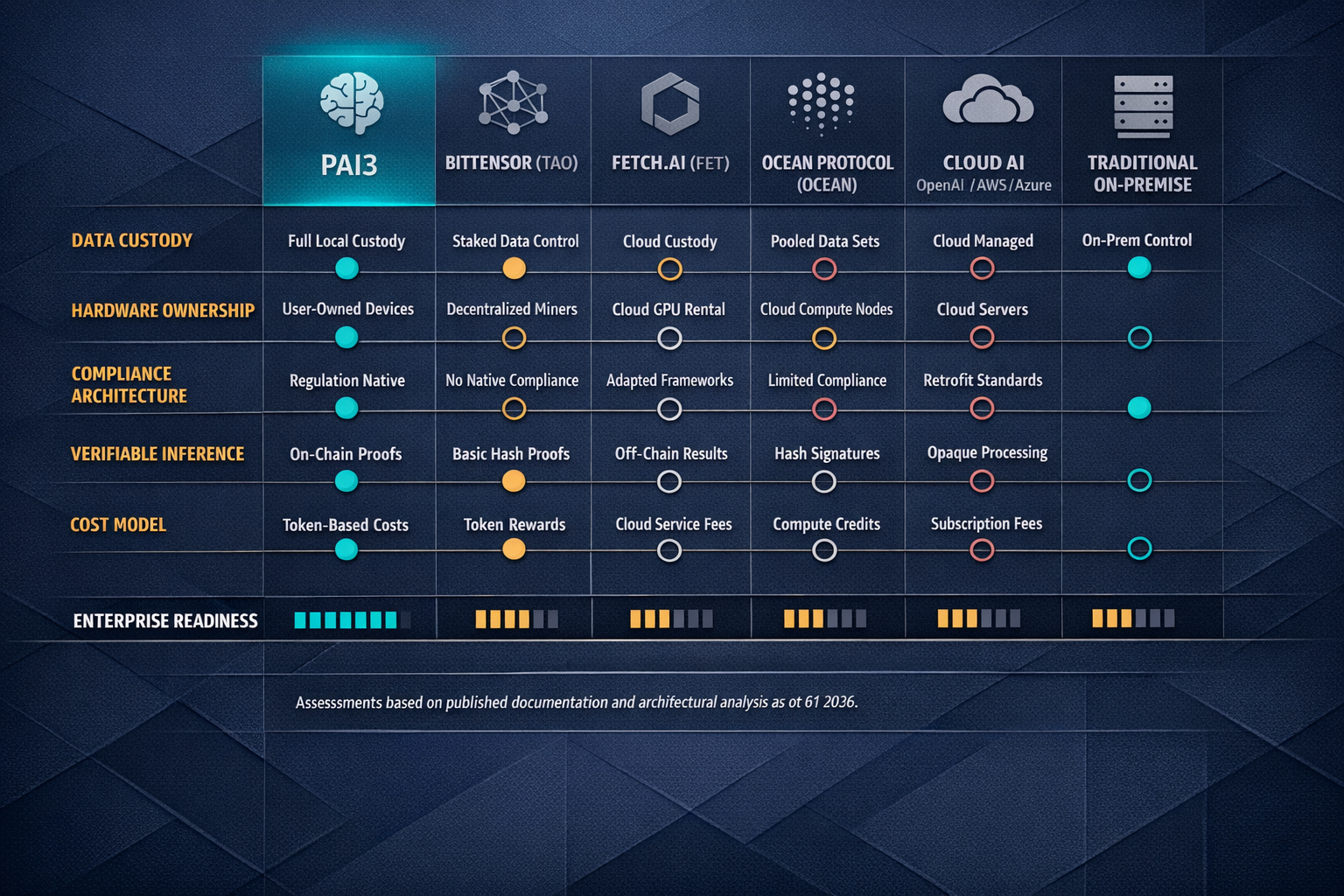
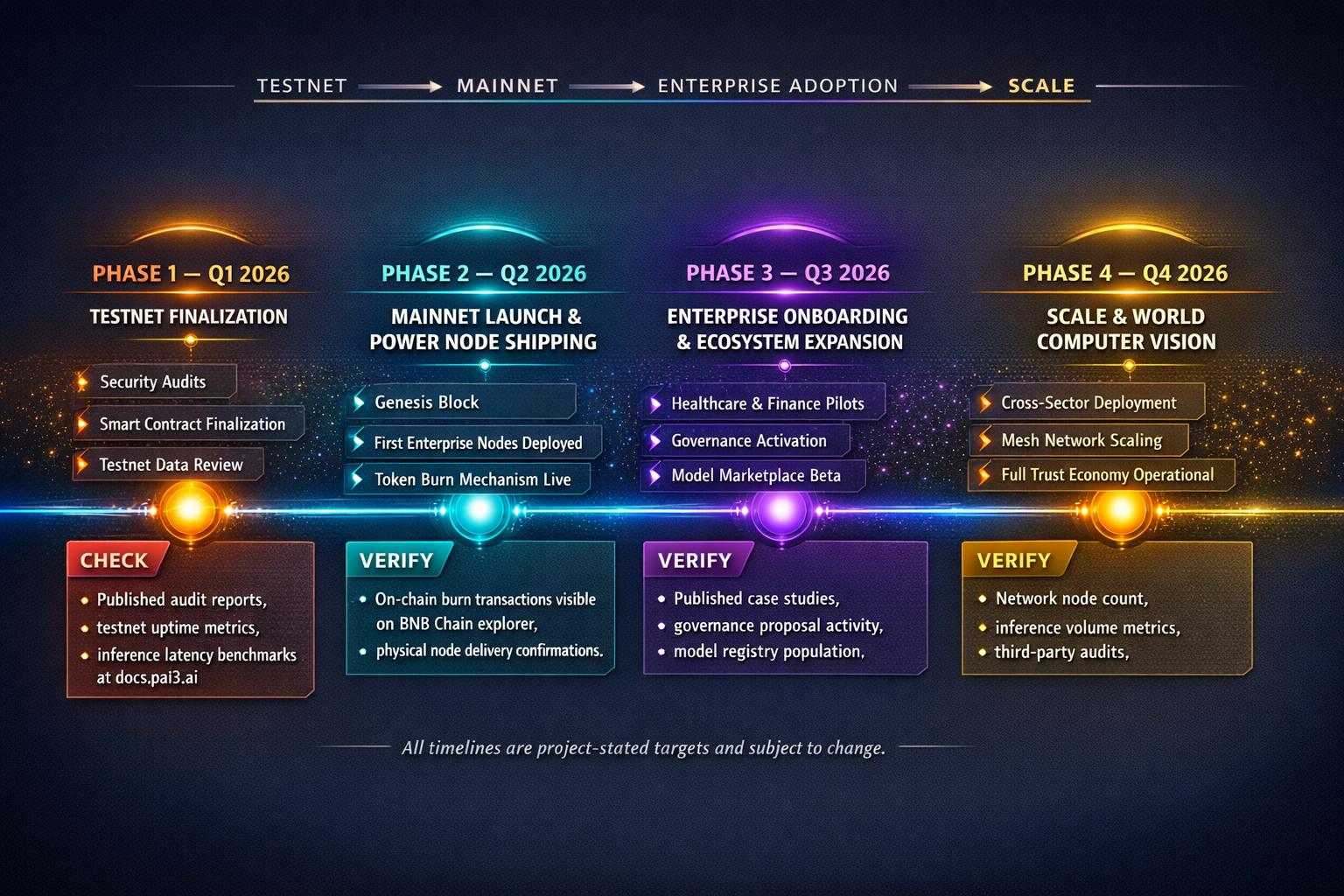
PAI3 (People's AI) is a decentralised AI infrastructure network built around precisely this inversion. Instead of uploading sensitive data to a remote server, organisations run inference locally on Power Nodes — physical hardware devices they purchase outright and install on their own premises. The node processes data locally; the data never traverses the network. What does traverse the network is compute coordination, model distribution and verifiable inference records — none of which contain the sensitive payload. This is not a theoretical design document. According to PAI3's own March 2026 communications, 500+ Power Nodes have been sold, 40+ enterprise partners span healthcare, government and finance, and the testnet has been live since Q3 2025. These figures are self-reported by the project and have not been independently audited or verified by a third party — enterprise evaluators should request supporting documentation before relying on them. The $PAI3 token launch is targeted for Q2 2026, with mainnet — the "World Computer" — targeted for Q3 2026.
This guide breaks down how PAI3's architecture maps to the compliance requirements of each sector, what the current state of the network is according to the project's own disclosures, where the critical risks and dependencies lie, and how to evaluate it against competing projects and alternative architectures.
⚠ Common mistake: Assuming "decentralised AI" means your sensitive data gets distributed across random people's computers. PAI3's architecture does the opposite — sensitive data stays exclusively on your local node. The mesh network coordinates which node handles which workload and distributes model updates, not patient records or financial data. However, note that inference attestation metadata recorded on-chain could potentially reveal information about the nature, timing and volume of inference operations — enterprises should assess this metadata leakage risk as part of their deployment planning.
---